





Where data sets breaks down...
time to read 6 min | 1014 words
Another thing that came up in conversation today, a very good example of where the data set model breaks down. Take a look at the following (highly simplified) tables:
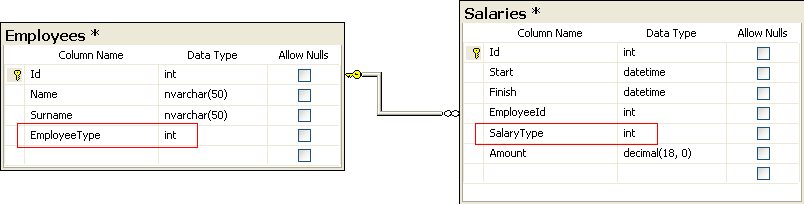
Each type of employee gets a different salary calculation for overtime per the (current) salary type:
| Global | Hourly | Global + Hourly | |
| Manager | None | 15% over hourly rate | 15% over hourly rate, to a max of totally 20% of monthly salary over a calendar month |
| Employee | None | 12% over hourly rate | 12% precentage |
| Freelance | 10$ hour | 9% over hourly rate | 10$ hour or 9% over hourly rate, lowest one |
Given the above business rules, how do you propose to write the AddOverTime() method using the dataset model in a maintainable fashion? There will be additonal employee types and additional salary types in the future.
Comments
Comment preview